グループ化してデータを出力
テスト用データセットの作成
まず、データセットの中身を次のようにする。
for (int i = 1; i <= 10; i++)
{
for (int j = 1; j <= 10; j++)
{
// Table1の新しい行を生成
HiraDataSet.Table1Row tr = (HiraDataSet.Table1Row)ds.Table1.NewRow();
tr.BeginEdit();
tr.key1 = i;
tr.key2 = j;
tr.str = "ひらてすと";
tr.val1 = 100;
tr.val2 = 200;
tr.EndEdit();
// 最後にデータセットに追加する
ds.Table1.Rows.Add(tr);
}
}
よくあるデータでは、key1が部門コード、key2が社員コード、みたいな感じだ。
レポートの設定
縦にデータを出した例もグループ化しているといえばしている。
その単位は、ページだ。
ページが変わると、新たに、ページヘッダを出力し、詳細のデータを出力し、そして、ページフッタを出力する。
そして、また、新しいページへと続く。
グループ化してデータを扱うためにはをグループを利用する。
「グループ名フィールド」を右クリックして、
グループの挿入を選択すると、
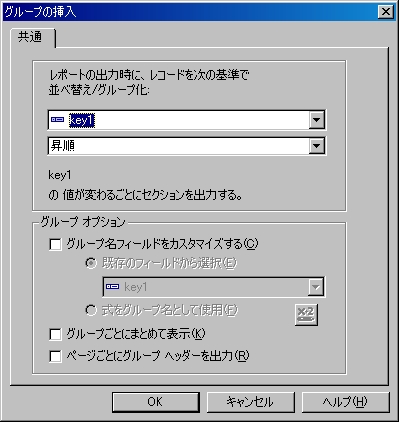
こんな画面になる。
ちなみに、データベースフィールドを設定しておかないと、このメニューは出ない。
とりあえず、一番上の「key1」というあたりがポイントだ。
これを元にしてグループ化する。
今回はこのまま、昇順に並び替えた「key1」をキーにして、グループ化する。
これは、
| key1 | key2 | ???? |
|---|
| 1 | 1 | A |
| 1 | 2 | B |
| 1 | 3 | C |
| 2 | 1 | D |
| 2 | 2 | E |
| 3 | 1 | F |
となっている場合に、ABC, DE, F という単位で固めるということだ。
決定すると、

という感じになる。
詳細を挟むような形で、グループヘッダー、グループフッターが出来ている。
グループヘッダーにある「グループ名 #1」はTable1.key1を指す別名だ。
気に入らなかったら、消してTable1.key1を貼り付けても同じことだし、必要なければなくてもよい。
大事に取ってはおきたいが、内容を編集したい場合は、右クリックして、「選択エキスパート」を選択する。

今回はこんな風にしてみた。
出力

こんな感じ。
しかし、なんとなく気に入らない。
グループヘッダのkey1と「ひらてすと」のあるデータの行が空いている。
なんというか、
ではなく、
としたいわけだ。
これは、やり方はいろいろあるが、とりあえず、簡単なところで、「セクションの書式」の「グループヘッダ」のところで設定できる。
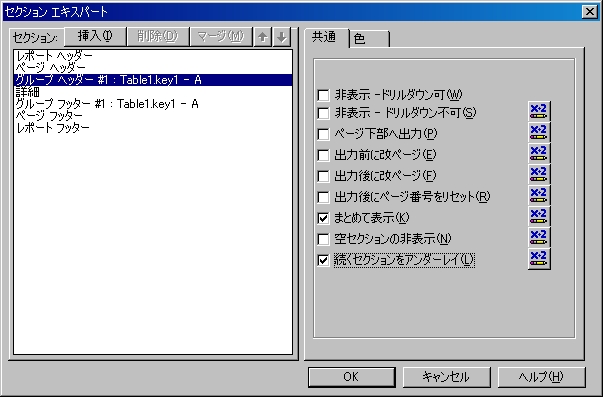
ここの、「続くセクションをアンダーレイ」にチェックを入れると、次のセクション、つまり、次の行が重なって表示される。

いかかだろう。
少しはよくなっただろうか。
[home]
[クリスタルレポートトップ]